

History: 알고리즘 대회에 필요한 수학
WORK IN PROGRESS
작업중
WORK IN PROGRESS
작업중
WORK IN PROGRESS
작업중
WORK IN PROGRESS
작업중
이산 수학
점화식 풀이 기법들
- 2차 선형동차점화식 (Linear homogenous recurrence)
- 다음과 같은 형태: a_{k} = \alpha \cdot a_{k-1} + \beta \cdot b_{k-2}.
- a_{n}=r^{n} 꼴이라고 생각하고 대입해 보면 r^{2} - \alpha\cdot r - \beta = 0을 얻는다. 이 방정식의 해 r에 대해 r^{n}은 해가 됨.
- 해가 둘 있을 경우, a\cdot r_{1}^{n} + b\cdot r_{2}^{n} 꼴의 선형 결합도 해가 된다 (당연). 이 계수들을 초기상태에 맞도록 지정.
- Application:
- 피보나치 수열의 일반항은?
- p의 확률로 이기는 bet을 한다. (승-패)가 W가 되거나 -L이 될 때까지 하는데, 이 때 W 승으로 끝날 확률은? (ICPC WF '13 B)
- 일반화: 3차, 4차, 5차.. 라도 같은 요령으로 풀 수 있다 (3차, 4차 방정식을 풀기 힘들어서 그렇지)
- 중근이면 어떻게? 만약 r이 m+1번 중근으로 등장한다면 r^{n}, n\cdot r^{n}, \cdots, n^{m}\cdot r^{n} 의 선형결합이 들어간다.
선형비동차점화식 (Linear non-homogenous recurrence)
- a_{k} = \alpha_{k-1}a_{k-1} + \cdots + \alpha_{k-n}a_{k-n} + f(n) (마지막의 f(n)에 주의!)
- 해법
- a_n = b_n + h_n으로 분해 (b_n은 점화식만 만족하고 초기상태는 만족하지 않는 답. 대개 f(n)과 비슷한 형태를 갖는다.
- h_n을 찾고 a_n의 계수를 초기상태 성립하도록 맞춰 주면 됨.
일반항 계산을 직접 하는 경우도 있지만 행렬의 형태로 표현하고 푸는 일이 많다.
- 예) 피보나치 수열의 n번째 수를 구하기 위해서는 \begin{bmatrix} F_{n+2} \\ F_{n+1} \end{bmatrix} = \begin{pmatrix} 1 & 1\\ 1 & 0 \end{pmatrix} \begin{bmatrix} F_{n+1} \\ F_{n} \end{bmatrix} 의 점화식으로부터 얻는 다음의 식을 이용해 계산한다. \begin{pmatrix} 1 & 1\\ 1 & 0 \end{pmatrix}^n \begin{bmatrix} 1 \\ 0 \end{bmatrix}
이항계수와 숫자 세기
- 이항계수 (Binomial coefficient): nCr = \left ( n \atop r \right ) = \frac{n!}{(n-r)!r!}
- 점화식: \left( n \atop r \right ) = \left( n-1 \atop r-1 \right) + \left( n-1 \atop r \right)
- Identity: \left( n \atop 0 \right ) = \left ( n \atop n \right ) = 1, \sum_{i=0}^{n}\left(n \atop i\right) = 2^{n}.
- 이항계수를 이용해 순열 수 세기: n개의 원소 중에서 r개를 뽑을 수 있는 경우의 수는?
- 유의해야 할 것
- 중복 여부: 같은 원소를 두 번 뽑을 수 있는가?
- 순서 여부: 같은 원소를 순서만 다르게 뽑았으면 다른 경우로 치는가?
- 공식
- 중복 없이, 순서 있을 때: \frac{n!}{(n-r)!} = nPr
- 중복 있고, 순서 있을 때: n^{r}
- 중복 없이, 순서 없을 때: \left ( n \atop r \right)
- 중복 있고, 순서 없을 때: \left ( n + r - 1 \atop r \right ) (n개의 원소와 r-1개의 막대기를 내려놓는 방법의 수)
- 유의해야 할 것
- 카탈란 수: 다양한 문제의 답이 된다.
- 예제 문제들: 길이가 2n인 괄호 수식의 수, n+1개의 리프를 가진 풀 바이너리 트리의 수, etc.
- 수식: C_n = \frac{1}{n+1} \left( 2n \atop n \right )
- Multinomial coefficient
- 탑코더 튜토리얼
포함-배제 법칙
- 공집합이 있는 n개의 집합의 합집합의 크기를 구하려면:
- 각 집합의 크기를 모두 더한다.
- 각 2개 집합에 대해 공집합의 크기를 모두 뺀다.
- 각 3개 집합에 대해 공집합의 크기를 모두 더한다.
- ...
- 탑코더 튜토리얼
- Application: Derangement 계산하기 - n개의 원소를 섞되, 그 중 아무 것도 원래 위치에 있지 않는 경우의 수는?
- Let: A_i = i가 제 자리로 간 순열의 개수.
- \sum_{i=0}^{n}(-1)^{n-i}\left( n \atop i \right)i!
- Moebius 함수와 반전 공식 - 약수/배수 관계를 이용한 포함-배제 법칙이 필요한 경우 이 함수로 답이 나타날 수 있다.
- n 이하의 Square Free 개수 세기 - \sum_{i \in \Bbb{Z}^+} \mu (i) \lfloor \frac{n}{i^2} \rfloor 가 답이 된다. \sqrt{n}까지만 계산해주면 원하는 개수가 나온다.
번사이드 정리
- 페트르님의 정리
- 경우의 수를 세는데, 특정 transform operation(회전, 반사, ..)해서 같은 경우들은 하나로 친다. 전체 경우의 수는?
- 각 operation마다 이 operation을 했을 때 변하지 않는 경우의 수를 센다 (단, "아무것도 하지 않는다"라는 operation도 있어야 함!)
- 전체 경우의 수를 더한 후, operation의 수로 나눈다. (답이 맞다면 항상 나누어 떨어져야 한다)
- Application:
- n\times n (n은 편의를 위해 짝수) 크기의 격자를 x개의 색깔로 칠하는 경우의 수는? 단 회전해서 같은 경우는 같은 것으로 친다.
- 아무것도 하지 않을 때: 모든 격자가 변하지 않는다. x^{n*n}
- 90도 회전, 270도: 4개씩 칸을 그룹지어, 각 그룹은 같은 색이어야 한다. 따라서 x^{n*n/4}
- 180도 회전: 2개씩 칸을 그룹지어, 각 그룹은 같은 색이어야 한다. 따라서 x^{n*n/2}개의 경우의 수
- 최종 답은 이들의 평균!
- 만약 n이 홀수라면 어떨까?
- n\times n (n은 편의를 위해 짝수) 크기의 격자를 x개의 색깔로 칠하는 경우의 수는? 단 회전해서 같은 경우는 같은 것으로 친다.
키르히호프 정리
- 그래프의 생성 수형도(흔히 말하는 스패닝 트리)의 경우의 수를 구하는 정리로 대수적 그래프 이론에서 공부하게 된다.
- 무향 그래프의 Laplacian matrix L를 만든다. 간단히 설명하면 (정점의 차수 대각 행렬) - (인접행렬)이다. L에서 행과 열을 하나씩 제거하고 이것을 L^*라 하자. 어느 행/열이든 관계 없다. 그래프의 생성 수형도의 개수는 \det (L^{*})이다.
- 예제: \rm{K}_4의 Laplacian matrix는 \begin{bmatrix} 3 & -1 & -1 & -1 \\ -1 & 3 & -1 & -1 \\ -1 & -1 & 3 & -1 \\ -1 & -1 & -1 & 3 \\ \end{bmatrix} 이다. 여기서 첫번째 행과 첫번째 열을 제거하면 \begin{bmatrix} 3 & -1 & -1 \\ -1 & 3 & -1 \\ -1 & -1 & 3 \\ \end{bmatrix} 이고 가우스 조단 방법을 쓰면 \begin{bmatrix} 1 & 1 & 1 \\ 0 & 4 & 0 \\ 0 & 0 & 4 \\ \end{bmatrix} 이 되어서 1 \times 4 \times 4 = 16으로 우리가 알고 있던 Cayley 정리에 의한 답인 4^{4-2} = 16과 같다.
생성함수
- 제대로 이 토픽을 다룰 필요는 없지만 경우의 수 문제를 다룰 때 쓰이는 경우가 있다.
- 1원짜리 동전 5원짜리 동전 8원짜리 동전을 이용해서 몇억원을 만드는 경우의 수를 구한다고 하자.
- (1 + x + x^2 + \cdots) (1 + x^5 + x^{10} + \cdots) (1 + x^8 + x^{16} + \cdots)를 전개하면 x^{몇억}의 계수가 답이 된다.
- 생성함수에서 해당 식은 \frac{1}{(1-x)(1-x^5)(1-x^8)} 으로 표현할 수 있다.
- 계산을 위해 다음을 생각해보자. 1,5,8의 최소공배수인 40을 써서 (1-x^{40})^3을 곱하면 (1+x+\cdots+x^{39})(1+x^5+\cdots+x^{35})(1+x^8+\cdots+x^{32})이다. 해당 식의 분자와 분모에 (1-x^{40})^3을 곱하는 것을 생각해주면 된다. 분자는 106차식이다. 107개 항으로 쪼개고 분모의 (1-x^{40})^3으로부터 얻어지는 계수를 곱해주고 더하면 원하는 답을 얻는다.
- 분모로부터 얻어지는 계수는 \sum{ {n+2 \choose 2} x^{40 n} } = \frac{1}{(1-x^{40})^3} 에서 얻는다. 이렇게 되면 항상 40의 배수이므로 유효하게 고려하는 항의 개수는 약 \frac{1}{40}으로 줄어든다.
- 이 예제처럼 터무니 없이 큰 범위에 대해 답을 계산해야할 때는 수식만 잘 다룰 줄 알면 쉽다. SRM 600.5의 1000점 문제는 이러한 방식으로 풀린다.
- 어떤 수열의 점화식을 알 때 수열의 합을 구할 때도 쓸 수 있다. \sum{a_n x^n} 꼴로 우리가 원하는 답이 표현되는 경우에 적용할 수 있다.
- 피보나치 수열의 power series가 유명한 예이다. s(x) := \sum{F_n x^n} = \frac{x}{1-x-x^2}임을 s(x) 정의와 점화식에서 얻을 수 있다. x가 수렴하는 범위(황금비의 역수보다 절대값이 작은 경우)에 있기만 하면 된다.
게임이론
스프라그-그룬디 정리
- 튜토리얼 링크, 탑코더 튜토리얼, 또다른 튜토리얼
- Nim 게임
- 규칙
- 조약돌 k 무더기가 있다고 하자. 각 무더기에 포함된 조약돌의 개수는 다를 수 있다.
- 각 플레이어는 무더기를 하나 선택해서 그 무더기에서 1개 이상의 조약돌을 가져온다. (무더기에 남은 조약돌을 전부 가져와도 된다.)
- 마지막 조약돌을 가져가는 플레이어가 승리한다.
- Nim 게임의 해법
- 각 무더기의 조약돌 수를 전부 XOR한다. 0이면 패배! 0 이상이면 승리!
- 규칙
- 일반화하기:
- 모든 impartial(어느 플레이어든지 놓을 수 있는 수가 같다), normal play(마지막에 수를 두는 사람이 이긴다) 게임은 비슷한 해법으로 풀 수 있다.
- 다음과 같은 규칙:
- 게임은 한 개 이상의 서브게임으로 구성된다.
- 각 서브게임은 상태들의 DAG로 구성된다.
- 각 플레이어는 하나의 서브게임을 골라 해당 서브게임의 상태를 한 번 움직인다.
- 더 이상 움직일 수 없는 사람이 진다.
- 다음과 같은 규칙:
- 어떻게 풀까?
- 게임의 각 상태에 대해 Grundy 수를 계산한다.
- 우선 하나의 서브게임만 보자.
- 지는 상태(마지막 상태)의 Grundy 수는 0이다.
- 그 외의 상태에서는 이 상태에서 나가는 상태들의 Grundy 수를 모은 뒤, 그 중에 포함되지 않은 가장 작은 0 이상의 정수(minimum excluded number)가 Grundy 수가 된다.
- 여러 개의 서브게임이 있다면 각 서브게임의 상태를 XOR한다.
- Nim에서는: n개의 조약돌이 남아있다면 Grundy 수는 n
- 모든 impartial(어느 플레이어든지 놓을 수 있는 수가 같다), normal play(마지막에 수를 두는 사람이 이긴다) 게임은 비슷한 해법으로 풀 수 있다.
- Application: fill in!
확률론
기대값의 선형성
- E(\sum_{i}A_i) = \sum_i E(A_i)
- 당연한 얘기같지만 가끔 예상치 못한 간단한 답을 준다! 합을 어떻게 나누느냐에 따라 중요.
- Application
- N+1층짜리 건물의 1층에 엘리베이터가 섰는데, M명이 탔다. 각 사람이 가는 층은 랜덤하게 결정된다. 엘리베이터가 서는 횟수의 기대값은?
- 각 층별로 설 때 1이 되는 indicator function의 기대치를 구해서 더한다.
- 또 다른 예제: 평면상에 N개의 점이 있다. 각 점마다 해당 점이 존재하거나 지워질 확률이 주어진다. Convex hull 넓이의 기대값은?
- 각 간선별로 외적값의 기대치를 더한다.
- N+1층짜리 건물의 1층에 엘리베이터가 섰는데, M명이 탔다. 각 사람이 가는 층은 랜덤하게 결정된다. 엘리베이터가 서는 횟수의 기대값은?
정수론
모듈라 연산
- N으로 나눈 결과값을 구할 때, 연산 중간 결과도 N으로 나눠도 된다.
- (a + b) \mathrm{mod}N = (a \mathrm{mod}N + b\mathrm{mod}N) \mathrm{mod}N
- (a - b) \mathrm{mod}N = (a \mathrm{mod}N + b\mathrm{mod}N + N) \mathrm{mod}N
- (a * b) \mathrm{mod}N = (a \mathrm{mod}N * b\mathrm{mod}N) \mathrm{mod}N
- 단 나눗셈에는 성립하지 않는다. a로 나누기 위해서는, 곱셈의 역원을 대신 곱해줘야 한다. 모듈라 곱셈의 역원은 두 가지 방법으로 구할 수 있다.
- 한 가지 방법은 오일러 정리를 이용하는 것이다.
- a^{\phi(N)} \equiv 1 (\mathrm{mod}N)
- 이 때 phi(N)은 오일러 피 함수. 아래를 참조하라. 단 이거 계산하는건 배보다 배꼽이 더 클 수도.
- N이 소수라면 \phi(N)=N-2이니 간단.
- 이것을 거듭제곱 빨리 구하기로 구하면 된다.
- 두번째 방법(아마 더 효율적)은 확장 유클리드 알고리즘을 쓰는것이다. 아래를 참조하라.
- 한 가지 방법은 오일러 정리를 이용하는 것이다.
확장 유클리드 알고리즘
- 목적: 상수 a, b에 대해 ax + by = \mathrm{gcd}(a, b)를 만족하는 x, y를 찾아준다.
- Naive derivation:
- 유클리드 gcd 알고리즘에서, gcd()의 입력이 되는 숫자들은 항상 최초 숫자들의 선형 결합으로 표현할 수 있다.
- 따라서 각 숫자 a와 b를 넘길 때, 이들을 최초 숫자들의 선형 결합으로 표현한 방법 또한 넘겨주면 간단하게 풀 수 있다.
- 물론 이대로 구현하면 아주 귀찮다. 대신에 gcd(a, b) 함수가 최대공약수와 함께 ax+by=g 의 해 x, y를 반환하도록 하면 쉽게 풀 수 있다.
C++ 구현
struct Solution { int gcd, x, y; };
Solution extendedEuclid(int a, int b) {
int q = a / b, r = a % b;
if(r == 0) return Solution{b, 0, 1};
Solution s = extendedEuclid(b, r);
// now, we have
// s.gcd = s.x * b + s.y * r
// = s.x * b + s.y * (a - q * b)
// = s.y * a + (s.x - q * s.y) * b
return Solution{s.gcd, s.y, s.x - q * s.y};
}
- Application:
- 위에서 얘기했듯이, 모듈라 연산에서 곱셈의 역원 구하기. \mathrm{mod } N인 모듈로 연산을 할 때, a와 N이 서로소라 하자. (N이 소수면 항상 참) 따라서 a와 N의 egcd 결과는 항상 ax + Ny = 1이 된다. N로 나눠보면 ax = 1 (\mathrm{mod }N). 따라서 x는 a의 곱셈 역원이다. (단, 결과값이 음수라면 N을 더해줘야 함)
중국인 나머지 정리
뤼카의 정리
- 음이 아닌 정수 m, n과 임의의 소수 p에 대해 {m \choose n}\pmod p를 계산하는 정리이다.
- m과 n을 p진법으로 전개하여 그 p진 숫자를 m_i와 n_i라고 하자. 자리수가 다르면 0을 채워넣어 맞춰준다. 그러면 {m \choose n}\equiv\prod{m_i \choose n_i}\pmod p이다.
- 이 때 m_i < n_i이면 {m_i \choose n_i} = 0으로 취급한다.
오일러 피 함수, 약수의 합(시그마) 함수, 약수의 개수 함수, 뫼비우스 함수
- 이 함수들은 서로소인 것들에 대해 multiplicative 함수들이기 때문에 n 이하의 모든 값을 계산해야할 경우 에라토스테네스의 체를 이용하면 O(n log n)에 된다.
- 오일러 피 함수는 자신보다 작은 서로소인 정수의 개수를 나타내는 함수이다.
- \varphi(n) =n \prod_{p\mid n} \left(1-\frac{1}{p}\right)이고, 소인수 분해한 경우를 생각하면 계산하기 쉽다.
- 어떤 정수가 있을 때, p_i를 소인수라고 하고 a_i를 p_i 소인수의 거듭제곱 횟수라고 하자. 약수의 합(x=1), 약수의 개수(x=0) 함수는 \prod(1+p_i^{x}+\cdots+p_i^{x a_i})로 계산할 수 있다.
- 뫼비우스 함수는 \sum_{d | n} \mu(d) = \begin{cases}1&\mbox{ if } n=1\\ 0&\mbox{ if } n>1.\end{cases}를 사용해 계산할 수 있다.
- 이 함수들의 관계는 위키피디아 링크를 참고
분할 정복을 이용한 빠른 수식 계산
빠른 거듭 제곱 계산
- 분할 정복:
- x^{2n} = (x^n) \cdot (x^n)
- x^{(2n+1)} = x \cdot x^{2n}
빠른 등비 수열의 합
- 분할 정복:
- A^{2n} + A^{2n-1} + A^{2n-2} + \cdots + A^{1}
- = (A^{2n} + A^{n}) + (A^{2n-1} + A^{n-1}) + \cdots
- = (1 + A^n)(A^{n} + A^{n-1} + \cdots + A^{1})
행렬의 합
- 수열에 대한 테크닉을 바로 쓸 수도 있지만 I-A의 역행렬이 있는 경우에는
- \begin{align} I + A + A^2 + \cdots + A^{n-1} & = (I - A^n)(I-A)^{-1}\\ \end{align}
- 무한히 더해야 할 때, 합이 수렴하는 경우 (I-A)^{-1}이 답이 된다.
선형 시스템
가우스 소거법
심플렉스법
- 진짜로 이거 필요할까? -_-
리니어 시스템과 플로우
기초 수치 해석
Newton method
- 가장 기초적인 근 찾기(root-finding) 알고리즘. f(x)와 f'(x)의 구현이 주어질 때, f(x)=0인 위치를 찾는다.
- 처음에 답이 x_0이라고 찍어보자. f(x_0)을 계산해보니 0이 아니었다. 그러면 어떻게 할까?
- 좋은 방법은 f(x)를 선형함수로 근사하고, 이 경우 해가 되는 위치가 어디일지를 찾는 것이다. 다음 그림을 참조하자. (출처
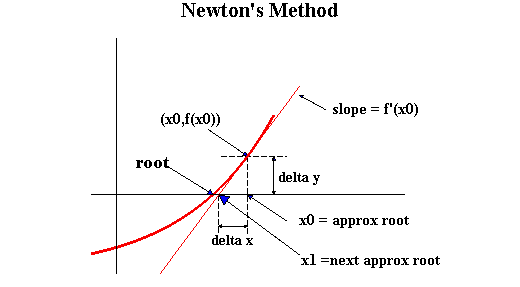
C++ 구현
// f(x)와 f'(x), 초기값이 주어졌을 때 해를 찾는다.
template<typename Function1, typename Function2>
double newton(Function1 f, Function2 fp, double init, double tolerance=1e-8, int iterations=10000) {
double x = init;
while(iterations--) {
double fx = f(x);
if(fabs(fx) < tolerance) return x;
double fpx = fp(x);
x -= fx / fpx;
}
// did not converge!
return x;
}
Adaptive Simpson 수치 적분
- f(x) 함수의 구현이 주어질 때, 해당 함수를 여러번 호출해서 해당 함수의 부정적분 없이도 정적분을 계산하는 기법들.
- Simpson법은 해당 함수를 2차함수로 근사해서 적분한다. 따라서 해당 함수가 2차 이하라면 항상 정확한 답이 나온다.
- Adaptive Simpson 적분 알고리즘은 해당 함수가 2차 함수에서 얼마나 벗어나는지 확인하고, 많이 벗어난다면 분할 정복한다. 자세한 백그라운드는 나도 모르니 싣지 않는다. 구현은 다음과 같다.
C++ 구현
template<typename Function>
double simpson(Function f, double a, double b) {
double c = (a + b) / 2.0;
double h3 = fabs(b - a) / 6.0;
return h3 * (f(a) + 4.0 * f(c) + f(b));
}
// sum은 처음에 simpson(f, a, b)로 초기화한다.
// 오차가 eps 이상으로 추정되는 경우 분할정복한다.
template<typename Function>
double adaptiveSimpson(Function f, double a, double b, double sum, double eps) {
double c = (a + b) / 2.0;
double left = simpson(f, a, c);
double right = simpson(f, c, b);
if(fabs(left + right - sum) <= 15 * eps)
return left + right - (left + right - sum) / 15;
return adaptiveSimpson(f, a, c, left, eps/2) + adaptiveSimpson(f, c, b, right, eps/2);
}
긴 정수 곱셈
카라츠바 알고리즘
- 카라츠바 알고리즘은 긴 정수 둘을 곱하는 분할 정복 알고리즘이다. B진수 n자리 긴 정수 a, b를 곱한다고 하자. (n은 2의 자승으로 가정한다.)
- 이 때 두 숫자를 모두 절반(n/2 자리씩)으로 다음과 같이 자르자.
- a = a_{1} \times B^{n/2} + a_{0}
- b = b_{1} \times B^{n/2} + b_{0}
- 이 때 다음과 같이 두자.
- z_0 = a_0 \times b_0
- z_2 = a_1 \times b_1
- z_1 = (a_0 + a_1) \times (b_0 + b_1) - z_0 - z_1 = a_0 \times b_1 + a_1 \times b_0
- 그러면
- a \cdot b = (a_1 \cdot B^{n/2} + a_0) \cdot (b_1 \cdot B^{n/2} + b_0) = (a_1 \cdot b_1) \cdot B^{n} + (a_0 \cdot b_1 + a_1 \cdot b_0) \cdot B^{n/2} + (a_0 \cdot b_0)
- = z_2 \cdot B^{n} + z_1 \cdot B^{n/2} + z_0
- B^{n}으로의 곱은 선형시간에 할 수 있다는 점을 감안하면, n/2 크기의 정수 곱셈 세 번만 하면 되기 때문에 확실히 빠르다!
FFT와 다항식 곱셈
- 빠른 다항식 곱셈 알고리즘이 있으면 긴 정수 곱셈도 빠르게 할 수 있다. 긴 정수를 몇 자리씩 끊어서 다항식의 계수로 삼은 뒤, 두 다항식을 곱하고, 마지막에 올림 처리만 해 주면 되기 때문.
- 다항식 곱셈 또한 물론 단순한 방법은 O(n^2)인데, FFT를 이용하면 O(n \lg n)에 할 수 있다.
- FFT 곱셈은 다항식에 두 가지 표현 방식이 있다는 것을 이용한다:
- 계수 목록 형태: 대부분 사용하는 방식
- x, y쌍 형태: 2n개의 상수 x_0, x_1, \cdots, x_{n-1}에 대해 f_(x_0), f_(x_1), \cdots를 저장하는 방식
- n개의 샘플은 n차 방정식을 유니크하게 정의하기 때문에 이 두 표현 방식은 동등하다.
- 하지만 f(x)\cdot g(x)를 x, y쌍 형태에서는 그냥 원소별로 곱해주면 된다!
- FFT는 특정 성질을 띠는 x들을 선택해, 이 두 형태간의 변환을 O(n \lg n)에 수행한다.
- 곱셈 자체는 O(n)이다.
- 자세히는 인간적으로 CLRS를 보자...
C++ 구현:
#include<vector>
#include<complex>
#include<cmath>
using namespace std;
typedef complex<double> Complex;
typedef vector<Complex> ComplexVector;
typedef vector<int> Polynomial;
const double PI = 2.0 * acos(0.0);
// Given a n-th polynomial p, return its values at
// w^0, w^1, .., w^(n-1). n is assumed to be a power of 2.
// Since the size of the input and output are the same, the output is stored at
// p.
void dft(ComplexVector& p, Complex w) {
int n = p.size();
if(n == 1) return;
// divide
ComplexVector even(n / 2), odd(n / 2);
for(int i = 0; i < n/2; ++i) {
even[i] = p[i * 2];
odd[i] = p[i * 2 + 1];
}
// conquer
dft(even, w * w);
dft(odd, w * w);
// merge
Complex w_power = 1;
for(int i = 0; i < n/2; ++i) {
Complex offset = w_power * odd[i];
p[i ] = even[i] + offset;
p[i + n/2] = even[i] - offset;
w_power *= w;
}
}
// returns smallest power of 2 s.t. p2 >= n.
int roundUp(int n) {
int p2 = 1;
while(p2 < n) p2 *= 2;
return p2;
}
Polynomial operator * (const Polynomial& a, const Polynomial& b) {
// last *2 is needed because C can have twice the degree from original polys
int n = roundUp(max(a.size(), b.size())) * 2;
// Complex representations of a and b
ComplexVector ac(a.begin(), a.end()), bc(b.begin(), b.end());
ac.resize(n);
bc.resize(n);
// FFT
Complex w = polar(1.0, 2 * PI / n);
dft(ac, w);
dft(bc, w);
// Pointwise multiplication
for(int i = 0; i < n; ++i)
ac[i] *= bc[i];
// Inverse FFT
dft(ac, polar(1.0, -2 * PI / n));
for(int i = 0; i < n; ++i)
ac[i] /= double(n);
// Trim zero paddings
while(!ac.empty() && fabs(real(ac.back())) < 1e-9)
ac.pop_back();
// return real
Polynomial ret(ac.size());
for(int i = 0; i < ac.size(); ++i)
ret[i] = int(round(real(ac[i])));
return ret;
}
긴 정수 곱셈의 응용
알면 유용한 사실들
- 약수의 개수: n의 약수의 개수는 2^{\log n / \log \log n} 이하 (by Severin Wigert) => 2^64이 최대이면 3321개 이하라는 상한이 있다.
- 원점에서 (a,b)까지 선분 위 격자점의 개수는 gcd(a,b)
- pi(x) ~= x/log(x)