

ACM-ICPC SWERC/2013
개요
2014년 05월 31일에 개최된 월파팀 연습대회에서 패배한 Balloonphilia 팀이 벌칙으로 작성하게 된 Editorial이다. 무슨 약을 하셨길래 이런 생각을... 조..좋은제도다
문제 목록
A. Mixing Colours
DP[i][j][c] = i번째 토큰 ~ j번째 토큰을 c색으로 합친 경우 log(cer)의 최댓값
(cer 들의 곱셈으로 연산을 하면 double로 해결이 불가하여 log들의 덧셈으로 식을 전환함)
위와 같이 DP배열을 정의하면 해결 할 수 있다.
DP[i][j][c] 가 갱신되는 경우는
c1+c2->c 가 가능하고 DP[i][k][c1] + DP[k+1][j][c2] > DP[i][j][c] 인 경우인데
c1+c2->c 가 가능해야 한다는 조건에 의해
각각의 i,j,k에 대해 총 R (색을 합치는 법칙의 갯수) 번의 갱신시도를 해주면 된다는 것을 알 수 있다.
for( i = 1 ~ n-1 ) for( j = 0 ~ n-i-1 ) for( k = j ~ j+i-1 ) for( l = 0 ~ R )
=> DP[ j ][ i+j-1 ][ l 번째 법칙의 합쳐진 후 색 ] 갱신 시도
이와 같이 해결하면 총 시간복잡도가 O(n^3*R) 이므로 n = 500 에 R = 100 인 상황이 부담스럽지만 제한시간이 10초이므로 서버를 믿고 믿는자에게 복이 있나니... 제출하도록 하자.
( 최악의 경우 500 * 250 * 125 * 100 = 약 15억 회의 갱신시도가 생긴다.)
이 때, DP배열을 double [500][500][300] 으로 잡았다가는 512M를 초과 할 수 있으니
double[500*250][300] 으로 선언하여 인덱스조정을 해주도록 하자.
B. It Can Be Arranged
아래와 같이 그래프를 구성한 후 MCMF 를 이용하여 해결한다.
- room[i] = course i 에 필요한 방의 갯수
- 1 <= i <= n 인 i에 대해 ( 0 노드 ) -> ( 2*i-1 노드 ) , 용량 INF, 비용 0 의 간선 추가
- ( 2i-1노드 ) -> ( 2*i 노드 ) , 용량 room[i], 비용 -1 의 간선 추가
- B[i]+clean[i][j] <= A[j] 인 i,j에 대해 ( course i 에 이용된 방이 j에도 이용 가능 ) ( 2i 노드 ) -> ( 2*j-1 노드 ) , 용량 INF, 비용 0 의 간선 추가
( 2*i 노드 ) -> ( 2*n+1 노드 ) , 용량 INF, 비용 0 의 간선 추가
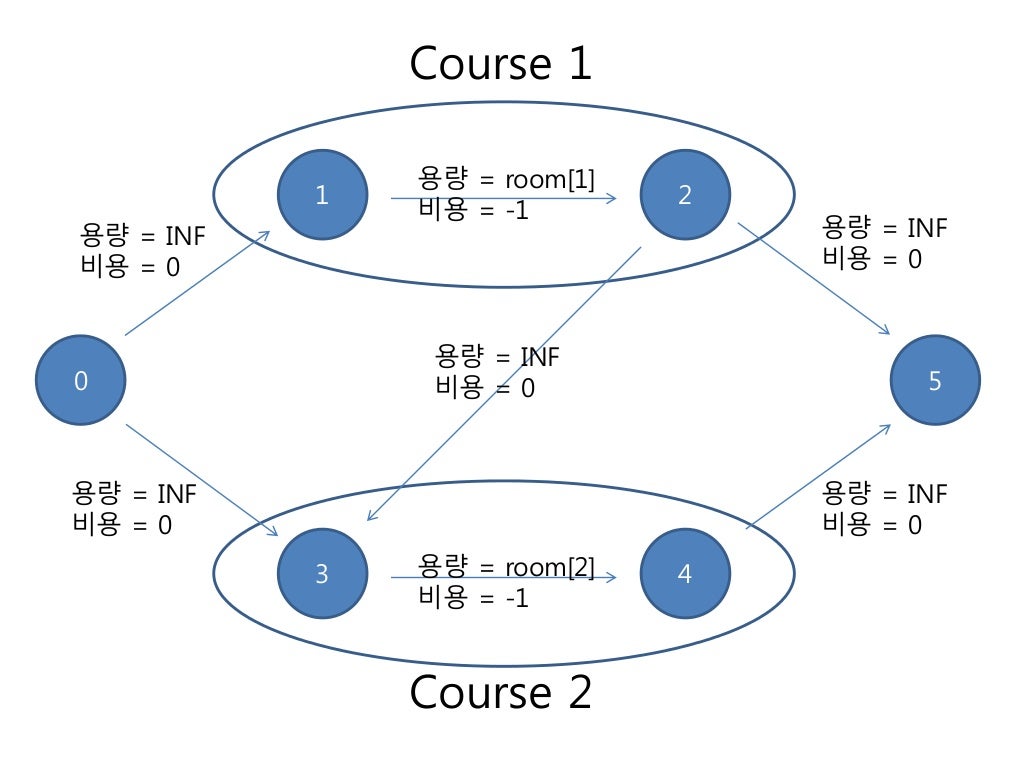
위와 같이 구성된 그래프에서 MCMF 알고리즘을 적용하였을 때 0번 노드에서 2*n+1 번 노드로 향하는 (각각의 용량이 1인) flow를 사용한 방으로 대응 시킬 수 있다.
위 그래프에서 0 -> 1 -> 2 -> 3 -> 4 -> 5 로 용량 1 인 flow
= Course 1 과 Course 2 에 사용된 방이 로 인해, "방 F 개로 모든 코스를 처리 할 수 있다" 와 "(유량 = F) 인 min cost flow 값이 -sum( room[i] ) 이다" 가 동치임을 알 수 있다.
이를 이용해 MCMF 알고리즘을 결과 값이 -sum( room[i] ) 가 될 때까지 돌려주면 필요한 최소의 방의 갯수를 확인 할 수 있다.
(다른 풀이)
Maximum Weighted Bipartite Matching을 이용해서 문제를 해결할 수도 있다. 문제를 살짝 바꿔보면, 우선 각각의 강의마다 필요한 강의실 수를 배정해준 뒤, 그 중 사용한 걸 최대한 재활용해주면 된다. 각각의 강의 u마다 정점 u, u'을 만들고, source->u인 간선의 capacity를 room[u], u'->sink인 간선의 capacity를 room[u]라 놓고, 어떤 강의 u에서 사용한 방을 강의 v에서 사용할 수 있으면, u->v'인 간선의 capacity를 inf로 놓고 이 그래프에서의 s-t flow값을 구한다. 답은 Sum(room[i]) - flow이다.
C. Shopping Malls
N<=200 이므로 문제에서 주어진 조건대로 그래프를 구성한 뒤 Floyd 알고리즘을 사용하여 모든 정점쌍에 대한 최단경로를 구할 수 있다. 그 후, 입력받은 각 쿼리에 대해 해당하는 경로를 출력해주면 된다.
D. Decoding the Hallway
이동경로를 나타내는 문자열을 구해놓고 답을 구하려고하면 안된다. n=1000일 경우 문자열의 길이가 2^1000 -1 이기 때문이다. 따라서 문자열을 생성하는 규칙을 찾아낸 뒤, 그에 맞춰서 문자열 S가 속하게 되는지를 판단하여야 한다.
우선 level이 한단계 높아지면서 추가되는 문자열들을 보자.

문제 설명에 따르면 처음에 반시계 방향으로 직각을 만들어내고 이후 번갈아가면서 시계, 반시계, 시계... 방향으로 직각을 만들어낸다고 되어있다.

이를 이용하면, n번째 문자열로부터 n+1번째 문자열을 만들기 위해선 위의 그림처럼, n번째 문자열 사이사이에 L과 R을 번갈아가면서 삽입하면 된다.
그렇다면 S가 부분문자열이 된다고 판단할까?
위의 문자열 생성하는 방식을 대충 보기좋게 만들면 아래와 같다.

문자열을 트리형태로 구성을 시킬 수 있다는 이야기다. 이제 전체 문자열이 트리형태로 생겼다고 치고, S가 이 트리 안으로 들어오는지를 판단해보자.
위의 생성된 트리의 규칙을 살펴보면 다음과 같다.
- k level 에서 L 과 R 사이에 반드시 k-1 level의 문자가 들어간다. (1<k<=n)
- k level 에 해당하는 문자들은 왼쪽에서부터 L과 R이 번갈아가면서 등장해야한다.
- 홀수 번 째 문자는 항상 n level의 문자이다.
1 level의 문자는 L이다.
S가 위의 규칙대로 생성된 문자열의 부분문자열이 되어야 한다. 그러기 위해 S에서 leap node(n level) 에 해당하는 문자가 무엇인지 결정을 하고, 규칙 1에 의거해서 level을 하나씩 줄여나가면서, 해당 level 에 속해있는 문자들이 누구누구인지를 결정해나가서, 마지막 1 level 에 해당하는 문자가 L이 나오면 된다. n level이 될 수 있는 경우는 2가지 뿐이고, k level 문자들이 결정되면 k-1 level의 문자가 될 수 있는 경우는 단 한가지 뿐이므로 시간안에 답을 구해낼 수 있다.
간단히 예를 들어보자. n = 4 일 때 S = LLRLLRR 이 속해있는지를 판단해보자.
S = L L R L L R R
B = X X X X X X X
↓ 4 level 결정
S = L L R L L R R
B = 4 X 4 X 4 X 4
↓ 3 level 결정
S = L L R L L R R
B = 4 3 4 X 4 3 4
↓ 2 level 결정
S = L L R L L R R
B = 4 3 4 2 4 3 4
↓ 1 level 결정
S = L L R L L R R
B = 4 3 4 2 4 3 41 level에 L과 R 둘 다 들어올 수 있는 상황이므로 L이 들어온다고 치면 부분문자열이 된다고 말할 수 있게된다.
이제 n = 4 일 때 S = RRR 이 속해있는지를 판단해보자.
S = R R R
B = X X X
↓ 4 level 결정
S = R R R
B = 4 X 4 <규칙 2 위반)
↓ 4 level 다시 결정
S = R R R
B = X 4 X
↓ 3 level 결정
S = R R R
B = 3 4 X (규칙 1에 의해)
↓ 2 level 결정
S = R R R
B = 3 4 X
(왼쪽 어딘가에 level 2에 해당하는 문자가 있을 것이다. 그 문자가 L이라고 가정을 한 채)
↓ 1 level 결정
S = R R R
B = 3 4 1L이 되던 R이 되던 상관없는 문자는 L로 결정하는게 포인트
n level이 될 수 있는 2가지 경우에 대해
첫 번 째 경우는 4 level에 해당하는 문자열이 L R L R 형태로 번갈아가면서 나타나지 않았기 때문에 실패했다.
마지막에 1 level에 해당하는 문자가 R로 결정됐는데, 1 level의 문자는 무조건 L이여야하므로 실패. 두 경우 모두답이 안된다고 말하고 있으므로, S는 부분문자열이 아니라고 말할 수 있다.
사실 입력되는 문자열의 길이가 짧기 때문에 n이 큰경우에 적절히 12정도로 줄여서 전체 문자열을 구한 후 검사해 보는 것으로도 답이 나온다.
E. Joe is learning to speak
map
각 단어들 사이에 공백을 한칸씩 두면 어떤 subsequence가 AB C 인지 A BC인지 명확하게 표시할 수 있다.
F. Odd and Even Zeroes
k = 5^k <= n && 5^(k+1) > n 인 자연수
zero(N) = N의 끝자리 0의 갯수
five(N) = N을 소인수분해했을 시 5의 차수
N! 을 소인수분해를 한 결과 2의 차수가 5의 차수보다 작은 경우는 존재하지 않으므로
zero(N!) = five(1)+five(2)+ ...+five(N) 임을 알 수 있다.
이 때, 5^k <= i && i <= n 인 i의 경우를 생각해 보면
five(i) = five(5^k+i-5^k) = five(i-5^k) 가 성립함을 알 수 있다.
( 5^(k+1) > n 으로 인해 five(i-5^k)<=k 이므로 소인수 분해했을 시의 식을 써보면 된다.)
zero(i!) = five(1) + ... + five(i) = five(1)+ ... + five(5^k) + five(1) + ... + five(i-5^k)
= zero((5^k)!) + zero((i-5^k)!)
우리가 구하고자 하는 0! ~ n! 중 zero() 값이 짝수인 경우의 수 인데 위의 식으로 인해
zero((5^k)!) 가 짝수인 경우
=> 0! ~ (5^k-1)! 중 zero() 값이 짝수인 경우의 수 + 0! ~ (n-5^k)! 중 zero() 값이 짝수인 경우의 수
zero((5^k)!) 가 홀수인 경우
=> 0! ~ (5^k-1)! 중 zero() 값이 짝수인 경우의 수 + 0! ~ (n-5^k)! 중 zero() 값이 홀수인 경우의 수위와 같이 식을 변형할 수 있음을 알 수 있다.
이제 이를 이용하여 recursive를 통해 해결하면 끝
(이 때, 0! ~ (5^k-1)! 중 zero() 값이 짝수인 경우의 수 는 가능한 k값이 몇개 되지 않으므로 저장이 가능하여 한번만 계산해 주면 된다.)
G. VivoParc
백트레킹을 통해 enclosure 들에 1,2,3,4 들을 답이 나올 때 까지 다 넣어 본다.
이 때, 현재 고를 수 있는 종의 갯수가 가장 적은 것부터 처리하며 만일 갯수가 같다면 간선의 갯수가 많은 것을 먼저 처리한다.
H. Binary Tree
우선 S를 따라 이동했을 때 현재 위치를 알고있어야 한다. 대충 Stack 형태로 저장이 되겠지..
그 다음 아래 3가지 변수를 관리해가면서, T를 따라 이동해 도착할 수 있는 node의 개수를 세면 된다.
p : L이 들어왔을 때 새로 추가될 node의 수
q : R이 들어왔을 때 새로 추가될 node의 수
r : 정답
처음 p,q,r 셋은 모두 1로 초기화 되어있다. 그 다음 L,R,U가 들어왔을 때 각각의 행동을 취하면 된다.
L : p개만큼 새로운 노드가 생성되었고, 각 p개의 node들은 2개의 자식노드를 가지고 있다. 따라서
r = r + p
p = (p - p) + p // p개의 노드 중 왼쪽 자식노드
q = (q ) + p // p개의 노드 중 오른쪽 자식 노드
R : q개만큼 새로운 노드가 생성되었고, 각 q개의 node들은 2개의 자식노드를 가지고 있다. 따라서
r = r + q
p = (p ) + q // q개의 노드 중 왼쪽 자식노드
q = (q - q) + q // q개의 노드 중 오른쪽 자식 노드
U : 골때리는 녀석이다. 현재까지의 명령을 통해 도착할 수 있는 노드들은 트리관계를 가지게 된다. 이런 트리에서, U 명령어에 의해서 영향을 받는 녀석은 최상단에 위치한 root node 하나 뿐이다.
만약 root node가 L 명령을 통해 도착한 녀석이라면, U 명령에 의해 새로 생성된 node는 오른쪽으로 움직일 수 있는 경우가 하나 추가되고, R 명령을 통해 도착한 녀석이라면 U 명령에 의해 새로 생성된 node는 왼쪽으로 움직일 수 있는 경우가 하나 추가된다. 즉
혅재 위치가 S의 L명령을 통해 도착했다면 ;
r = r + 1;
p = p
q = q + 1
혅재 위치가 S의 R명령을 통해 도착했다면 ;
r = r + 1;
p = p + 1
q = q
위의 일련의 과정을 통해 구해진 r을 출력하면 된다.
I. Trending Topic
map(string,int) 를 활용하여 지난 7일간 등장한 단어들의 등장 횟수를 관리하고 top N 쿼리가 주어지면 해당 map 의 모든 원소들을 주어진 조건으로 소팅하여 처리한다.
J. Cleaning the Hallway
이전에 알고스팟에 올라온 CIRCLES문제와 유사하다. 그러나 CIRCLES에서는 N개의 원의 합집합의 넓이를 구하는 것으로 끝이지만 이 문제는 N개의 도넛의 합집합의 넓이를 구해야 하기 때문에 조금 더 많은 예외처리를 필요로 한다.
우선 입력으로 주어진 도넛들에 그린 정리를 적용하기 위해 도넛의 바깥쪽 원과 안쪽 원을 두개의 폐곡선으로 떼어낸다. 그래서 바깥쪽 원은 반시계방향으로 적분, 안쪽 원은 시계방향으로 적분하면 원하는 넓이를 구할수 있게 된다.
이제 어려운 부분은 이 폐곡선들에서 적분하지 말아야 하는 구간을 찾는 것이다. 각각의 폐곡선들과 도넛의 위치관계를 정리하면 아래와 같다.
이제 구간을 잘 구했으면 구간에 속하지 않은 부분을 잘 적분하면 답을 구할 수 있다!